v1.74.9-stable - Auto-Router


Deploy this version
- Docker
- Pip
docker run litellm
docker run \
-e STORE_MODEL_IN_DB=True \
-p 4000:4000 \
ghcr.io/berriai/litellm:v1.74.9-stable
pip install litellm
pip install litellm==1.74.9.post1
Key Highlights
- Auto-Router - Automatically route requests to specific models based on request content.
- Model-level Guardrails - Only run guardrails when specific models are used.
- MCP Header Propagation - Propagate headers from client to backend MCP.
- New LLM Providers - Added Bedrock inpainting support and Recraft API image generation / image edits support.
Auto-Router
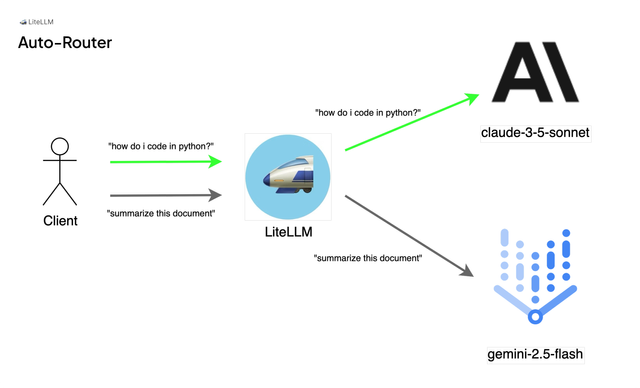
This release introduces auto-routing to models based on request content. This means Proxy Admins can define a set of keywords that always routes to specific models when users opt in to using the auto-router.
This is great for internal use cases where you don't want users to think about which model to use - for example, use Claude models for coding vs GPT models for generating ad copy.
Model-level Guardrails
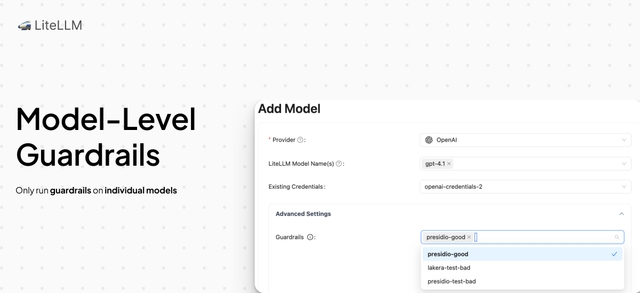
This release brings model-level guardrails support to your config.yaml + UI. This is great for cases when you have an on-prem and hosted model, and just want to run prevent sending PII to the hosted model.
model_list:
- model_name: claude-sonnet-4
litellm_params:
model: anthropic/claude-sonnet-4-20250514
api_key: os.environ/ANTHROPIC_API_KEY
api_base: https://api.anthropic.com/v1
guardrails: ["azure-text-moderation"] # 👈 KEY CHANGE
guardrails:
- guardrail_name: azure-text-moderation
litellm_params:
guardrail: azure/text_moderations
mode: "post_call"
api_key: os.environ/AZURE_GUARDRAIL_API_KEY
api_base: os.environ/AZURE_GUARDRAIL_API_BASE
MCP Header Propagation
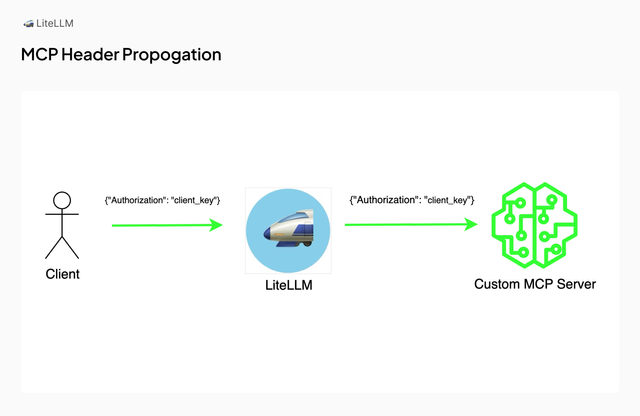
v1.74.9-stable allows you to propagate MCP server specific authentication headers via LiteLLM
- Allowing users to specify which
header_nameis to be propagated to whichmcp_servervia headers - Allows adding of different deployments of same MCP server type to use different authentication headers
New Models / Updated Models
Pricing / Context Window Updates
| Provider | Model | Context Window | Input ($/1M tokens) | Output ($/1M tokens) |
|---|---|---|---|---|
| Fireworks AI | fireworks/models/kimi-k2-instruct | 131k | $0.6 | $2.5 |
| OpenRouter | openrouter/qwen/qwen-vl-plus | 8192 | $0.21 | $0.63 |
| OpenRouter | openrouter/qwen/qwen3-coder | 8192 | $1 | $5 |
| OpenRouter | openrouter/bytedance/ui-tars-1.5-7b | 128k | $0.10 | $0.20 |
| Groq | groq/qwen/qwen3-32b | 131k | $0.29 | $0.59 |
| VertexAI | vertex_ai/meta/llama-3.1-8b-instruct-maas | 128k | $0.00 | $0.00 |
| VertexAI | vertex_ai/meta/llama-3.1-405b-instruct-maas | 128k | $5 | $16 |
| VertexAI | vertex_ai/meta/llama-3.2-90b-vision-instruct-maas | 128k | $0.00 | $0.00 |
| Google AI Studio | gemini/gemini-2.0-flash-live-001 | 1,048,576 | $0.35 | $1.5 |
| Google AI Studio | gemini/gemini-2.5-flash-lite | 1,048,576 | $0.1 | $0.4 |
| VertexAI | vertex_ai/gemini-2.0-flash-lite-001 | 1,048,576 | $0.35 | $1.5 |
| OpenAI | gpt-4o-realtime-preview-2025-06-03 | 128k | $5 | $20 |
Features
- Lambda AI
- New LLM API provider - PR #12817
- Github Copilot
- Dynamic endpoint support - PR #12827
- Morph
- New LLM API provider - PR #12821
- Groq
- Remove deprecated groq/qwen-qwq-32b - PR #12832
- Recraft
- Azure OpenAI
- Support DefaultAzureCredential without hard-coded environment variables - PR #12841
- Hyperbolic
- New LLM API provider - PR #12826
- OpenAI
/realtimeAPI - pass through intent query param - PR #12838
- Bedrock
- Add inpainting support for Amazon Nova Canvas - PR #12949 s/o @SantoshDhaladhuli
Bugs
- Gemini (Google AI Studio + VertexAI)
- Fix leaking file descriptor error on sync calls - PR #12824
- IBM Watsonx
- use correct parameter name for tool choice - PR #9980
- Anthropic
- Openrouter
- filter out cache_control flag for non-anthropic models (allows usage with claude code) https://github.com/BerriAI/litellm/pull/12850
- Gemini
LLM API Endpoints
Features
- Passthrough endpoints
- Make key/user/team cost tracking OSS - PR #12847
- /v1/models
- Return fallback models as part of api response - PR #12811 s/o @murad-khafizov
- /vector_stores
- Make permission management OSS - PR #12990
Bugs
/batches- Skip invalid batch during cost tracking check (prev. Would stop all checks) - PR #12782
/chat/completions- Fix async retryer on .acompletion() - PR #12886
MCP Gateway
Features
- Permission Management
- Make permission management by key/team OSS - PR #12988
- MCP Alias
- Support mcp server aliases (useful for calling long mcp server names on Cursor) - PR #12994
- Header Propagation
- Support propagating headers from client to backend MCP (useful for sending personal access tokens to backend MCP) - PR #13003
Management Endpoints / UI
Features
- Usage
- Support viewing usage by model group - PR #12890
- Virtual Keys
- New
key_typefield on/key/generate- allows specifying if key can call LLM API vs. Management routes - PR #12909
- New
- Models
Bugs
- SSO
- Guardrails
- Show correct guardrails when editing a team - PR #12823
- Virtual Keys
Logging / Guardrail Integrations
Features
- Google Cloud Model Armor
- Document new guardrail - PR #12492
- Pillar Security
- New LLM Guardrail - PR #12791
- CloudZero
- Allow exporting spend to cloudzero - PR #12908
- Model-level Guardrails
- Support model-level guardrails - PR #12968
Bugs
- Prometheus
- Fix
[tag]=falsewhen tag is set for tag-based metrics - PR #12916
- Fix
- Guardrails AI
- Use ‘validatedOutput’ to allow usage of “fix” guards - PR #12891 s/o @DmitriyAlergant
Performance / Loadbalancing / Reliability improvements
Features
- Auto-Router
- New auto-router powered by
semantic-router- PR #12955
- New auto-router powered by
Bugs
- forward_clientside_headers
- Filter out
content-lengthfrom headers (caused backend requests to hang) - PR #12886
- Filter out
- Message Redaction
- Fix cannot pickle coroutine object error - PR #13005
General Proxy Improvements
Features
- Benchmarks
- Updated litellm proxy benchmarks (p50, p90, p99 overhead) - PR #12842
- Request Headers
- Added new
x-litellm-num-retriesrequest header
- Added new
- Swagger
- Support local swagger on custom root paths - PR #12911
- Health
- Track cost + add tags for health checks done by LiteLLM Proxy - PR #12880
Bugs
- Proxy Startup
- Fixes issue on startup where team member budget is None would block startup - PR #12843
- Docker
- Separate Health App
- Pass through cmd args via supervisord (enables user config to still work via docker) - PR #12871
- Swagger
- Request Headers
- Make ‘user_header_name’ field check case insensitive (fixes customer budget enforcement for OpenWebUi) - PR #12950
- SpendLogs
- Fix issues writing to DB when custom_llm_provider is None - PR #13001
New Contributors
- @magicalne made their first contribution in https://github.com/BerriAI/litellm/pull/12804
- @pavangudiwada made their first contribution in https://github.com/BerriAI/litellm/pull/12798
- @mdiloreto made their first contribution in https://github.com/BerriAI/litellm/pull/12707
- @murad-khafizov made their first contribution in https://github.com/BerriAI/litellm/pull/12811
- @eagle-p made their first contribution in https://github.com/BerriAI/litellm/pull/12791
- @apoorv-sharma made their first contribution in https://github.com/BerriAI/litellm/pull/12920
- @SantoshDhaladhuli made their first contribution in https://github.com/BerriAI/litellm/pull/12949
- @tonga54 made their first contribution in https://github.com/BerriAI/litellm/pull/12941
- @sings-to-bees-on-wednesdays made their first contribution in https://github.com/BerriAI/litellm/pull/12950